

近日,一项发布于 GitHub 与 arXiv 的研究引发业界热议:华为推出的盘古大模型(Pangu Pro MoE)被发现与阿里巴巴达摩院发布的通义千问 Qwen-2.5 14B 模型在参数结构上“惊人一致”。
九游娱乐img.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2025%2F0704%2Ff130819cj00syvi13005wd200u000bag00gx006c.jpg&thumbnail=660x2147483647&quality=80&type=jpg width=609 height=228 />
该研究使用最新的“LLM 指纹”技术,指出两者之间在注意力权重输出空间的相似性高达0.927,远高于其他主流模型组合。
作者提出了一种黑盒大模型指纹识别技术,即便无法访问模型权重,也能通过 API 输出(如 logits 或 top-k 概率)判断模型之间是否存在归属或继承关系。
“盘古 Pangu Pro MoE 与 Qwen-2.5 14B 模型在注意力模块中呈现 极高相似性 ,而这在其他模型对比中从未出现。”
该结果意味着,Pangu 很可能在 Qwen 的基础上进行训练或修改,而非“从零自主研发”。
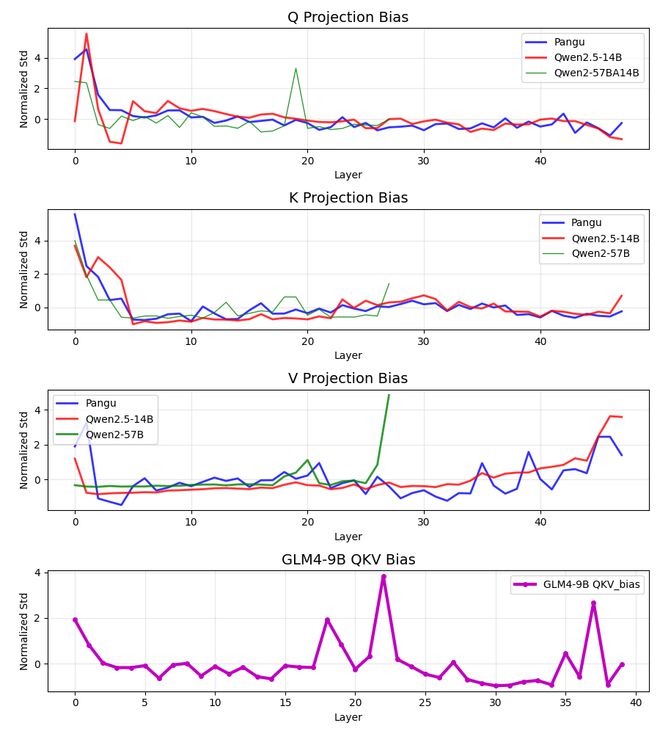
QKV 偏差分析显示,盘古模型和 Qwen2.5-14B 在三种投影类型(Q、K、V)上均表九游娱乐现出惊人的相似性。
这两个模型都表现出几乎相同的模式,尤其是在早期层的特征峰值以及随后的收敛行为方面。
鉴于 QKV 偏差是 Qwen 1代至2.5代的一个显著设计特征,而大多数开源模型(包括 Qwen3)放弃了这种方法,这一点尤为重要。
